
JPEG は非可逆圧縮の画像フォーマットとして有名です。今回は JPEG 圧縮するとどう劣化するのか、そしてそのメカニズムを紹介します。
圧縮率を上げる事により発生する劣化
JPEG で圧縮率をあげると以下のような現象が見られます。
モスキートノイズ
| 元画像(png) | q=100 | q=80 | q=40 | q=20 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
クオリティ1を下げると文字やその周りに汚れのようなノイズが発生しています。これはモスキートノイズやリンギングと呼ばれます。大きく色が異なる箇所付近に目立って発生します。
ブロックノイズ
| 元画像(png) | q=100 | q=60 | q=40 | q=20 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
なだらかだったグラデーションが、クオリティを下げると四角い形での歪みが見られるようになります。これはブロックノイズやブロック歪みと呼ばれています。
ポスター化
| 元画像(png) | q=20 | q=10 | q=5 | q=3 |
|---|---|---|---|---|
|
|
 |
 |
 |
さらにクオリティを下げると、グラデーションが荒くなり、色数が減っていきます。
JPEGの劣化を引き起こすメカニズム
ブロック分割
JPEG は 8x8 のブロック2に分割してそれぞれに対して圧縮処理を行います。そのため、圧縮による劣化はブロック単位で変わる事になり、ブロックの境界で劣化が目立つ事になります。これがブロックノイズとなって現れます。
| JPEG(2倍拡大) | 4倍に拡大 | 8x8で線を追加 |
|---|---|---|
 |
 |
 |
上の例でいうと、細かい劣化の目立つブロック(薄い赤い部分)と目立たないブロック(青い部分)の境界(赤い部分)で劣化が目立ちます。
離散コサイン変換と量子化
JPEG は各ブロックに離散コサイン変換という変換を施した形式で保存しています。
離散コサイン変換の詳細の説明は省きますが、JPEG の 8x8 のブロックに対して離散コサイン変換を施すと下図のような 64 種類のパターンの組み合わせに分解されて表現されるようになります。

例として「A」という文字の32x32(つまり4x4ブロック)の画像を離散コサイン変換します。
| 変換前 | 変換後の64パターン | 左上からブレンドするとこうなる |
|---|---|---|
 |
 |
 |
ポイントとしては、以下のようになります。
- 変換すると64種類のパターンに分解される
- 64種類のパターンをブレンド3するとちゃんと元の画像になる
左上のパターンは低周波成分と呼ばれ、ブロック全体の色を決めるのに使用します。一方で、右下のパターンは高周波成分と呼ばれ、ブロック内のより細かい色の変化を表現するのに使用します。
ところで、離散コサイン変換を行うだけでは画像の劣化は起きません4。しかし、JPEG ではさらに各パラメーターの値を近似値に丸めるため、それによって品質が劣化します。これを「量子化」と呼びます。
圧縮品質パラメーター
グラフィックソフトなどで JPEG を書き出す際に 0〜100 指定する品質を設定した経験があるかもしれません。100 の場合はほぼ正確な値を残すと思われますが、数値を下げると思い切った近似をするようになります。
実はこの数字によってどのような近似を行うかはソフトウェア毎に異なります5。なので、同じ品質の数値でもソフトウェアによっては劣化の仕方が変わります。
また、JPEG ではパターン(周波数)毎に近似の強さを変える事ができます。例えば、上の図で言う左上の低周波成分を強く近似すると、ブロックの色がまんべんなく変わります。一方、右や下のストライプや、右下のチェックのような高周波成分を近似すると、縞模様やチェックが浮き上がって来る事になります。これがモスキートノイズの原因になります。
高周波のパターンが人間には判別しづらい事がわかっているので、多くのソフトウェアでは左上よりも右下を優先的に近似をします。
JPEG の色空間とダウンサンプリングによる劣化
量子化によって情報を落としている事が JPEG の画質劣化の主な原因ですが、JPEG の画質に関しては YCbCr という色の表現方法を採用している事も関係しています。
YCbCr とモスキートノイズ
先ほどのモスキートノイズの画像を拡大してみます。
画像は白と赤しか使ってないにもかかわらず、うっすらと青いノイズが見えるのではないでしょうか。これは一般的な RGB ではなく YCbCr で表現している事から発生するものです。
YCbCr では色を輝度(Y)と二軸の色差で表現します。
| 元画像 | 輝度と色差 |
|---|---|
 |
 |
JPEG では Y/Cb/Cr それぞれの成分に対してブロック分割し、圧縮を行います。そのため、圧縮に伴う歪みは「輝度の歪み」と「色差の歪み」という形で発生します。
例えば、輝度成分に対してモスキートノイズが発生すると、縞模様やチェック状の「輝度の歪み」が発生します。一方で色差成分に対してモスキートノイズが発生すると、縞模様やチェック状の「色差の歪み」が発生します。先ほどの画像で青いノイズが発生したのは、色差成分のモスキートノイズが原因です。
クロマサブサンプリング
JPEG では上で説明した量子化による情報の切り落としの他に、色差の情報を落とす事があります。
例を挙げてみます。以下は品質を100の状態でPNGからJPEGに変換したものです。
| 元画像(png) | q=100 |
|---|---|
 |
 |
最高品質にしたのにもかかわらず、緑と紫のチェックがグレー6になってしまいました。ストライプの部分もぼんやりと色がついているもののほぼグレーです。
この劣化はクロマサブサンプリングと呼ばれる操作が行われているのが原因です。クロマサブサンプリングは YCbCr の色差成分を縮小する事でデータ量を減らす方法で、人間が色の変化よりも明度の変化に敏感であることを活用しています。サブサンプリングの方式は 4:4:4 (間引かない)、4:2:0 (縦横方向で半分間引く)、4:2:2 (横方向だけ間引く)などがあります。上の例では 4:2:0 の形式でサブサンプリングを行っています7。
| 4:4:4(間引かない) | 4:2:0 | 4:2:2 |
|---|---|---|
 |
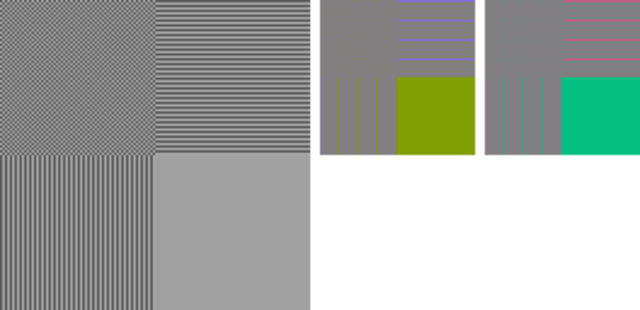 |
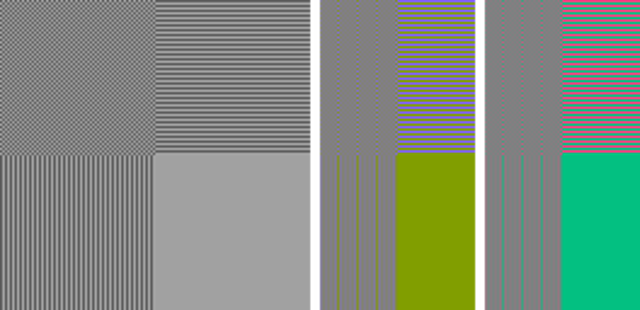 |
クロマサブサンプリングとブロックノイズ
JPEGのブロック化や離散コサイン変換の処理は、クロマサブサンプリングされたものに対して行われます。そのため、色差成分に関してはより広い範囲(4:2:2だと16x8、4:2:0だと16x16)でブロックノイズが発生します。
| 元画像(png) | q=20(4:4:4) | q=20(4:2:2) | q=20(4:2:0) |
|---|---|---|---|
|
|
 |
 |
-
JPEG への変換は ImageMagick 7.0.9-8 を使用しています。 ↩︎
-
8x8 以外のサイズに指定する事も可能です。 ↩︎
-
グレーより明るい色でブレンドするとより明るくなり、暗い色でブレンドするとより暗くなる、といったブレンドになっています。 ↩︎
-
実際には丸め誤差で小さな劣化が発生します。 ↩︎
-
Independent JPEG Group という団体により作られた方法が一般的ですが、例えば Adobe 製品はこれとは別の独自の量子化ロジックを使っているようです。 ↩︎
-
なおこの画像は色差の平均をとるとグレーになるように調整しています。エンコーダー(ImageMagickが使っているlibjpegだと思われます)が平均値をとってサブサンプリングを行っているため、このようになっています。写真の場合はこのように極端な色差の劣化が発生する事は少ないと思われます。 ↩︎
-
ImageMagick のデフォルト ↩︎

この記事を書いた人:鷲田
ルームクリップのアプリケーションエンジニア。
